
TL;DR:
- El machine learning permite que los sistemas aprendan y mejoren sin programación explícita.
- Existen tres tipos principales: supervisado, no supervisado y por refuerzo, según el problema.
- La calidad de los datos y el proceso de entrenamiento son clave para resultados efectivos.
El machine learning ya no vive solo en laboratorios de grandes empresas tecnológicas. Está en tu bandeja de entrada cuando Gmail filtra el spam, en Netflix cuando te sugiere una serie y en el GPS cuando recalcula tu ruta en tiempo real. Según AWS, el machine learning es una rama de la inteligencia artificial que permite a los sistemas aprender y mejorar a partir de datos sin programación explícita. Eso significa que la tecnología aprende sola, a partir de ejemplos, igual que tú aprendiste a reconocer caras sin que nadie te explicara cada rasgo. Este artículo te explica qué es, cómo funciona y qué debes saber para empezar a entenderlo.
Tabla de contenidos
- Definición y principios básicos del machine learning
- Los tipos principales de machine learning y cuándo se usan
- Cómo funciona una solución de machine learning paso a paso
- Retos y matices en machine learning: qué debes vigilar
- Una mirada realista al potencial y límites del machine learning
- Aprende más sobre tecnología y machine learning en TecnoHoy
- Preguntas frecuentes sobre machine learning
Puntos Clave
| Punto | Detalles |
|---|---|
| Aprendizaje basado en datos | El machine learning permite que ordenadores aprendan patrones útiles de grandes volúmenes de datos sin programación explícita. |
| Varios tipos y usos | Existen técnicas supervisadas, no supervisadas y por refuerzo, cada una para distintos desafíos tecnológicos. |
| Proceso estructurado | Crear modelos ML requiere pasos claros: datos, entrenamiento, evaluación y monitoreo, con calidad como factor clave. |
| Desafíos y límites | Problemas como overfitting o sesgos exigen validación rigurosa y datos adecuados para evitar errores y falsos positivos. |
| Aplicación cotidiana | El machine learning está en los servicios de uso común, desde emails hasta compras en línea y asistentes inteligentes. |
Definición y principios básicos del machine learning
Una vez que sabemos que el machine learning es parte de la vida diaria, conviene entender realmente en qué consiste y qué lo hace tan valioso.
El machine learning, o aprendizaje automático, es la capacidad de un sistema informático para mejorar su rendimiento en una tarea concreta a partir de la experiencia, es decir, de los datos. No se trata de programar cada regla manualmente. En cambio, el sistema recibe ejemplos y deduce las reglas por sí mismo. Eso es lo que lo diferencia de la automatización tradicional, donde un programador escribe instrucciones fijas para cada situación posible.
“El machine learning permite a un sistema aprender e identificar patrones en grandes volúmenes de datos.”
La inteligencia artificial tradicional funcionaba con reglas escritas por humanos: si pasa X, haz Y. El machine learning invierte esa lógica. El sistema observa miles o millones de ejemplos y construye sus propias reglas internas. Por eso puede adaptarse a situaciones nuevas que nadie anticipó.
Algunos ejemplos cotidianos que ya conoces:
- Filtros de spam: Tu correo analiza patrones en miles de mensajes para decidir qué es basura y qué no.
- Recomendaciones de contenido: Spotify y YouTube aprenden tus gustos observando qué escuchas o ves más tiempo.
- Asistentes de voz: Siri y Google Assistant mejoran su comprensión del habla con cada conversación.
- Detección de fraude: Los bancos identifican transacciones sospechosas comparando tu comportamiento habitual con el actual.
Lo que hace poderoso al machine learning es que puede encontrar relaciones en datos que un humano jamás detectaría manualmente. Si quieres dar tus primeros pasos en este campo, explorar cómo empezar con IA es un buen punto de partida antes de profundizar en los algoritmos.
En esencia, el machine learning cambia la tecnología porque permite crear soluciones que se adaptan, que mejoran con el tiempo y que pueden operar en contextos donde las reglas fijas simplemente no funcionan.
Los tipos principales de machine learning y cuándo se usan
Comprendida la base, es importante distinguir los tipos más populares de machine learning y cuándo elegir cada uno.
No existe un único tipo de machine learning. Cada enfoque responde a un tipo de problema distinto. Según SAP, los tipos principales son supervisado, no supervisado y aprendizaje por refuerzo. Entender la diferencia entre ellos te ayuda a saber qué herramienta usar en cada situación.
| Tipo | Cómo aprende | Ejemplo real | Limitación principal |
|---|---|---|---|
| Supervisado | Con datos etiquetados | Detección de spam, diagnóstico médico | Requiere muchos datos etiquetados |
| No supervisado | Sin etiquetas, busca patrones | Segmentación de clientes, análisis de mercado | Resultados más difíciles de interpretar |
| Por refuerzo | Por ensayo y error con recompensas | Videojuegos, robots, trading algorítmico | Muy costoso computacionalmente |
El aprendizaje supervisado es el más usado en la práctica. El modelo aprende a partir de ejemplos donde ya conocemos la respuesta correcta. Si tienes 10.000 correos etiquetados como spam o no spam, el modelo aprende a clasificar correos nuevos. Su limitación es que necesita grandes cantidades de datos etiquetados, y etiquetar datos manualmente es costoso.
El aprendizaje no supervisado trabaja sin etiquetas. El modelo busca agrupaciones o patrones ocultos en los datos. Es ideal cuando no sabes exactamente qué estás buscando, como cuando quieres segmentar a tus clientes por comportamiento sin haberlos clasificado antes. El reto es que interpretar esos grupos requiere criterio humano.
El aprendizaje por refuerzo funciona como entrenar a un perro: el modelo recibe una recompensa cuando acierta y una penalización cuando falla. Aprende por prueba y error. Es el enfoque detrás de los sistemas que juegan ajedrez o Go mejor que cualquier humano, y también de algunos robots industriales.
Para saber cuándo aplicar cada tipo, sigue estos pasos:
- Define claramente el problema que quieres resolver.
- Evalúa si tienes datos etiquetados disponibles.
- Determina si buscas predecir, clasificar o descubrir patrones.
- Considera los recursos computacionales disponibles.
- Elige el tipo de modelo que mejor encaje con esas condiciones.
Consejo profesional: Si estás empezando, el aprendizaje supervisado es el punto de entrada más accesible. Tiene documentación abundante, herramientas maduras y resultados más predecibles. Puedes ver cómo se aplica en contextos reales en esta guía sobre IA en pequeñas empresas.
Evitar los errores comunes en machine learning desde el principio te ahorrará semanas de trabajo mal orientado.
Cómo funciona una solución de machine learning paso a paso
Saber los tipos es útil, pero aún más valioso es entender cómo es el proceso de aplicar machine learning en la práctica.
Una solución de machine learning no aparece de la nada. Sigue un flujo de trabajo estructurado que va desde los datos brutos hasta un modelo funcionando en producción. Según Glyph Signal, las etapas del machine learning incluyen recopilación y preparación de datos, selección de algoritmo, entrenamiento, evaluación, despliegue y monitoreo.

| Etapa | Qué ocurre | Error frecuente |
|---|---|---|
| Recopilación de datos | Se obtienen datos relevantes y representativos | Usar datos sesgados o incompletos |
| Preparación | Limpieza, normalización y transformación | Saltarse esta etapa por impaciencia |
| Selección de algoritmo | Se elige el modelo adecuado al problema | Elegir el más complejo sin justificación |
| Entrenamiento | El modelo aprende de los datos de entrenamiento | Entrenar con pocos datos o datos sucios |
| Evaluación | Se mide el rendimiento con datos nuevos | Evaluar solo con datos de entrenamiento |
| Despliegue | El modelo se integra en un sistema real | No preparar la infraestructura adecuada |
| Monitoreo | Se vigila el rendimiento en producción | Olvidarse del modelo una vez lanzado |
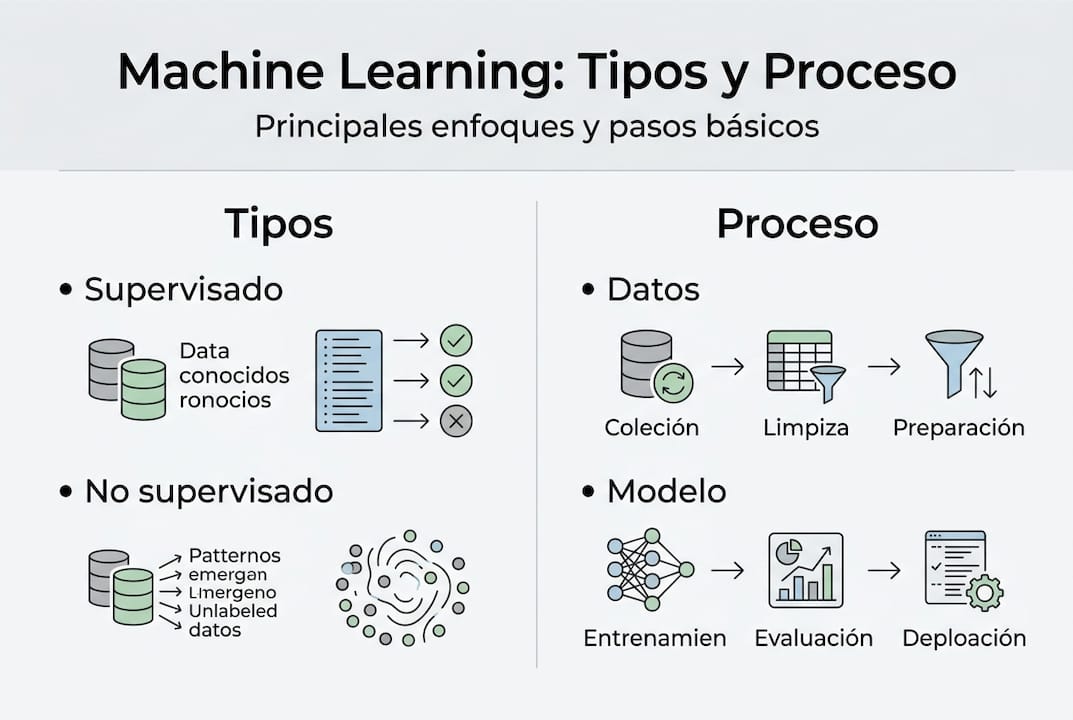
El proceso empieza siempre con los datos. Sin datos de calidad, el modelo no puede aprender nada útil. Esta fase de recopilación y limpieza suele consumir entre el 60% y el 80% del tiempo total del proyecto, algo que sorprende a quienes imaginan que la parte difícil es el algoritmo.
Los pasos clave en orden son:
- Recopilar datos relevantes y suficientes para el problema.
- Limpiar y preparar los datos: eliminar duplicados, tratar valores faltantes, normalizar formatos.
- Seleccionar el algoritmo más adecuado según el tipo de problema.
- Entrenar el modelo con una parte de los datos.
- Evaluar el rendimiento con datos que el modelo no ha visto antes.
- Desplegar el modelo en el entorno real donde se usará.
- Monitorear continuamente para detectar degradación del rendimiento.
Los roles involucrados incluyen científicos de datos, ingenieros de machine learning y expertos en el dominio del problema. Ninguno puede trabajar solo con éxito. Si te interesa aplicar este proceso para automatizar tareas con IA en tu día a día, el flujo anterior es el esquema mental que necesitas. También puedes ver cómo las personas más productivas usan IA para productividad sin necesidad de ser expertos técnicos.
Retos y matices en machine learning: qué debes vigilar
Una vez entendido el proceso, hay que atender las dificultades más frecuentes que pueden complicar el éxito del machine learning.
Tener un buen algoritmo no garantiza buenos resultados. El machine learning tiene trampas que incluso profesionales experimentados caen. Según AWS, problemas como overfitting, underfitting y sesgos pueden impactar gravemente los resultados de machine learning.
El overfitting ocurre cuando el modelo aprende demasiado bien los datos de entrenamiento, incluyendo el ruido y las anomalías. El resultado es un modelo que funciona perfectamente en el entrenamiento pero falla en datos reales. Es como memorizar las respuestas de un examen sin entender el tema.
El underfitting es el problema opuesto: el modelo es demasiado simple y no captura los patrones relevantes. Funciona mal tanto en entrenamiento como en producción. Suele ocurrir cuando se usa un algoritmo poco potente para un problema complejo.
Los sesgos son quizás el problema más serio. Si los datos de entrenamiento reflejan prejuicios históricos, el modelo los aprenderá y los amplificará. Sistemas de selección de personal entrenados con datos históricos han discriminado candidatos por género o etnia sin que nadie lo programara explícitamente.
Algunas señales de alerta que debes vigilar:
- El modelo tiene un rendimiento muy alto en entrenamiento pero bajo en validación (overfitting).
- El modelo falla por igual en todos los conjuntos de datos (underfitting).
- Los resultados favorecen sistemáticamente a ciertos grupos sobre otros (sesgo).
- El rendimiento del modelo cae semanas después del despliegue sin cambios aparentes (degradación).
“Un modelo de machine learning no es más inteligente que los datos con los que aprendió. La basura entra, la basura sale.”
Consejo profesional: Usa siempre un conjunto de validación cruzada para evaluar tu modelo. Divide tus datos en al menos tres partes: entrenamiento, validación y prueba. Nunca evalúes el rendimiento final con los mismos datos con los que entrenaste. Revisar los errores frecuentes en IA antes de lanzar cualquier proyecto puede ahorrarte problemas serios.
Técnicas como la regularización, el data augmentation y la validación cruzada existen precisamente para mitigar estos riesgos. No son opcionales en proyectos serios.
Una mirada realista al potencial y límites del machine learning
Habiendo revisado los desafíos, ponemos en perspectiva el verdadero impacto del machine learning y los errores de interpretación más comunes.
El machine learning es una herramienta extraordinariamente poderosa, pero no es magia. Uno de los errores más comunes es esperar que un modelo resuelva problemas que en realidad son problemas de estrategia, de datos o de definición del problema. Ningún algoritmo puede compensar datos mal recopilados o un objetivo mal planteado.
Hay algo que los titulares tecnológicos rara vez mencionan: los modelos simples a menudo superan en valor práctico a los modelos complejos. Un modelo de regresión lineal bien calibrado puede ser más útil para una pequeña empresa que una red neuronal profunda que nadie entiende ni puede mantener. La complejidad tiene un coste real en tiempo, dinero e interpretabilidad.
Según Glyph Signal, el machine learning depende de datos de calidad y no es magia; la interpretación humana es esencial. Eso significa que el criterio de quien diseña el sistema, define los objetivos y evalúa los resultados sigue siendo irreemplazable.
Si estás considerando aplicar machine learning en tu negocio o proyecto, empieza por preguntarte si tienes datos suficientes y representativos, si el problema está bien definido y si tienes capacidad para mantener el modelo en el tiempo. Explorar las aplicaciones prácticas de IA que ya existen puede darte una perspectiva más honesta de lo que es posible hoy.
Aprende más sobre tecnología y machine learning en TecnoHoy
Si te interesa aplicar el machine learning en tu contexto, accede a recursos y tutoriales especializados en TecnoHoy.
En TecnoHoy encontrarás guías paso a paso diseñadas para personas que quieren entender y usar tecnología sin necesidad de ser ingenieros. Desde cómo aprender cualquier tecnología desde cero hasta recursos prácticos sobre IA, automatización y seguridad digital. Si quieres proteger tus proyectos digitales mientras avanzas, el checklist de seguridad digital es un recurso que no deberías saltarte. Y cuando estés listo para ir más allá, la guía para dominar una herramienta digital te dará el marco mental que necesitas para aprender con eficiencia real.
Preguntas frecuentes sobre machine learning
¿Cuál es la diferencia entre machine learning e inteligencia artificial?
El machine learning es una rama específica de la inteligencia artificial centrada en que los sistemas aprendan sin programación explícita, mientras la IA abarca técnicas más amplias como la lógica simbólica y los sistemas expertos.
¿Qué ejemplos prácticos de machine learning vemos en la vida diaria?
Desde los filtros de spam en el email hasta las recomendaciones de películas o asistentes de voz, usamos machine learning a diario casi sin notarlo.
¿Cuáles son los errores más comunes al implementar machine learning?
Depender de datos poco representativos, crear modelos demasiado complejos o no validar bien los resultados son errores típicos, y problemas como overfitting pueden arruinar un proyecto bien intencionado.
¿Por qué es clave la calidad de los datos en machine learning?
Sin datos confiables y representativos, incluso el mejor modelo produce resultados incorrectos, porque el machine learning depende directamente de la información con la que aprende.